As I near the completion of my PhD journey, I wanted to share some common challenges that many of us face @DCoP_Innovators. The genetic architecture of PD is inherently complex, but as researchers, we sometimes add to this complexity due to a lack of standardization—whether it’s in the genes included, the methods used to prioritize variants, or the way GBA1 variants are classified. Maybe it could have some nice output DCI Resources and Coordination, as the task force led by @ehutchins and @malosco last year
Below, I summarize four studies—three of them very recent, and one that I hold in high regard for its clarity and the important differences it highlights:
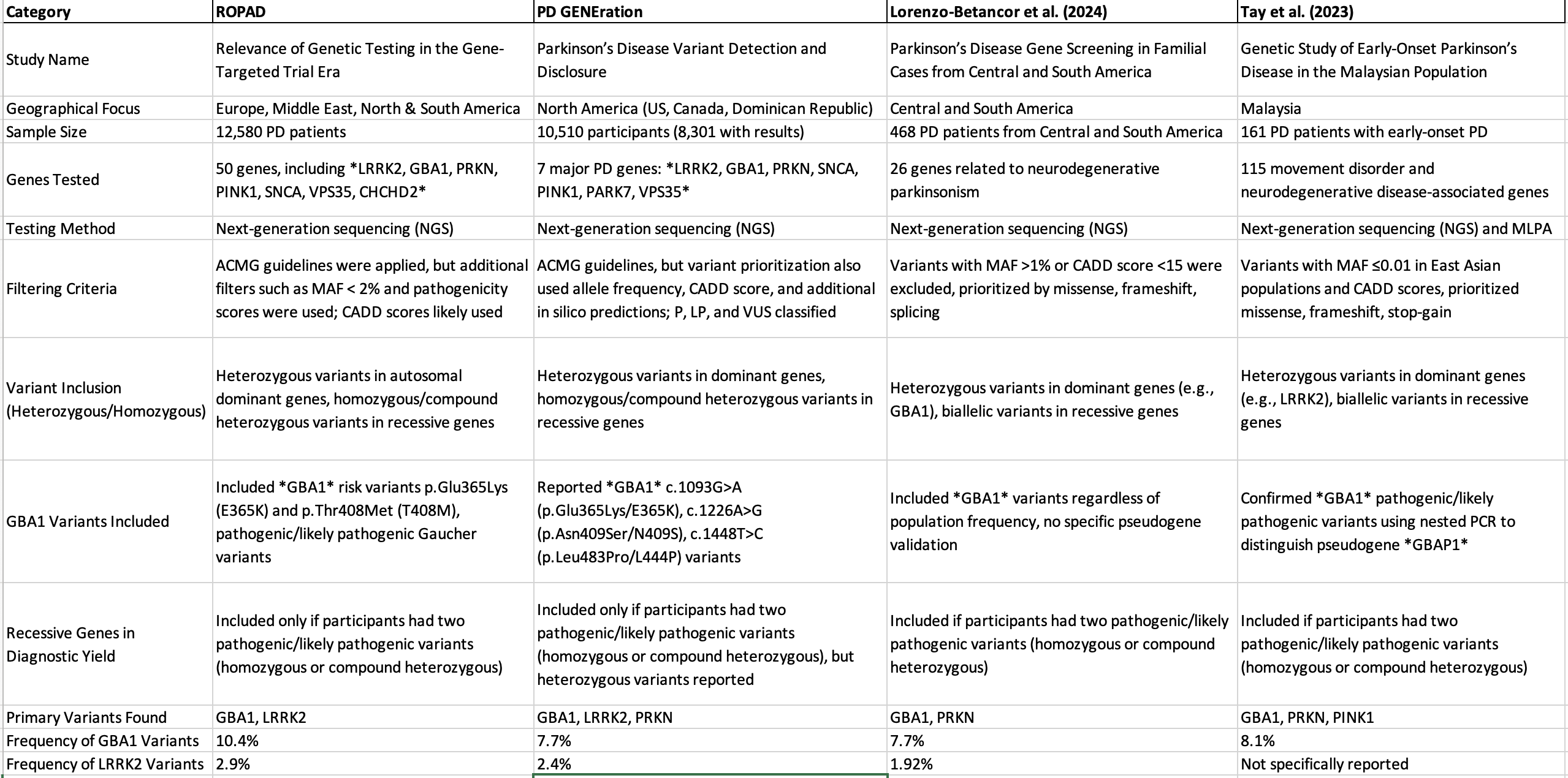
As you see, there are key gaps that the Data Community of Practice could tackle to bring more cohesion and comparability to PD research:
1. Genes Included
There is a clear need for a standardized approach to the genes included in PD genetic studies. While I follow the MDS nomenclature, during my thesis work, I encountered missing PD-related genes such as CHCHD2, DNAJC12, JAM2, MYORG, SYNJ1, and XPR1 in the TrusightOne panel, from Illumina, that includes 4811 genes!!!. Furthermore, how can we expedite the study of newly emerging genes like RAB32?
2. Variant Filtering and Curation
The variant filtering and curation methodologies differ significantly across studies. There should be a best practice approach, particularly tailored for PD, that streamlines variant prioritization, filtering, and reporting. A standardized method would ensure more reliable and comparable results across different research projects. (And save us a lot of time)
3. GBA1: Which Variants and Which Classification?
GBA1 remains a challenging gene in PD genetics, with different guidelines or suggested ways to classify and report variants. Should we focus only on pathogenic variants, or include risk factors as well? If we aim for a stricter way of doing thinks, we should apply the 2024 ClinGen Low Penetrance/Risk Allele Working Group guidelines for risk allele curation and reporting. This offers a more focused approach than the widely used ACMG/AMP 2015 standards for pathogenic variant classification, which is intended for monogenic disorders.
I’d love to hear your thoughts on how we can collaborate to bring more cohesion to PD research. @paularp @victorfloresocampo have you encountered the same issues? others in training how have you addressed these gaps?
I’d love to hear all your thoughts, as this is a topic where collaboration can make a real difference:
- The clinical perspective: @Vidash @gdp22 @yasser.mecheri @Maouly @elahif01
- The genetics angle: @joanne.trinh
- The epidemiological insights: @fbbriggs
- The bioinformatics and data science perspective: @peixott @vdardov @AmgadDroby @jf.daneault
- And from those who bridge medicine and bioinformatics: @hirotaka @danieltds
Hope to hear from you soon!!!